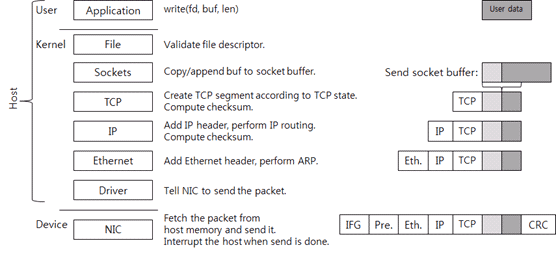
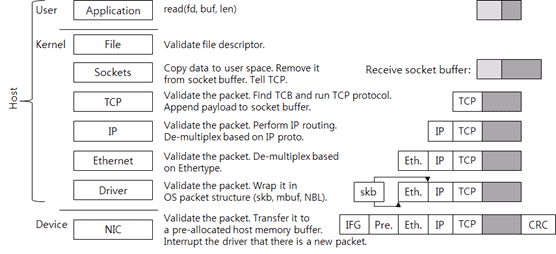
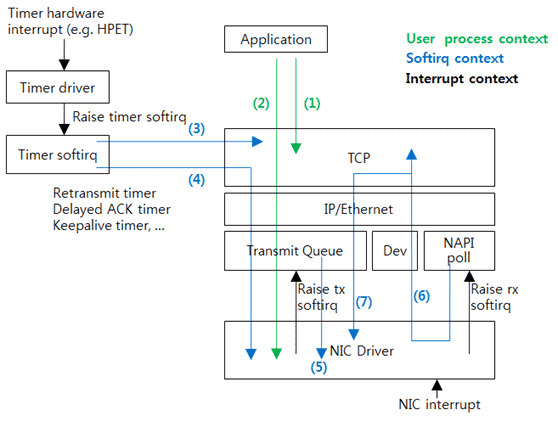
学习了解一下微信的后端存储架构。使用微信的过程中就能发现微信不像QQ并没有漫游所有聊天信息,记录基本完全是在本地存储的,因此后台存储难度应该不大。
视频与ppt地址,演讲人微信基础平台组许家滔sunnyxu
主要介绍内部产品QuorumKV,具体关注kv系统的强一致性。
需求背景:微信全球数据布局分在上海,天津,深圳,香港,加拿大,乃至同城多园区分布等等
系统要求:分布式强一致性(不需要应用层再设计),同城园区灾备,类SQL查询
存储信息:聊天记录,通讯录,个人信息,朋友圈
存储介质:包含mem,ssd,sas
增加数据流程:实现方法为分组
序列号发生器:微信后台与终端交互使用序列号进行数据同步,偏序,实现方法为仅一个client操作
(如果还要实现后来这些需求,前面这些hack实现是否有必要?)
修改value:1.可以覆盖;2.可以根据条件修改;实现方法为每次变更选举(by key),分为1.检查版本号;2.向集群发出请求;3.收到请求检查版本号;4.返回选举结果;5.推送结果;(类似Raft?)
问题:容灾成本仍然高(预留机器空间)
权衡点:自治,负载均衡,扩散控制
解决方案:六台机作为一组(挂一台20%增长)跨园区跨机分组
数据sharding:均匀分布指定分段(先算好后直接用,更好可以用hash ring,为何不用一致性hash?可能不均匀与冲突,负载均衡问题),希望终端无状态可以方便的重启防止内存泄露

底层使用所谓bitcask(内存索引加顺序写),同时使用小表系统解决写放大问题
同步流量要求幂等,为每个数据块记版本号,在某个版本号进行某个操作,保底策略:某台机器刚启动问题会要求对端发完整数据块
通信包量:读写的动态合并
异步化:协程,libco